📅 Free webinar · 9 July, 1-1.30pm BST - Three moments that decide whether a shopper buysSave your seat
Woosmap Geocoding API Error Handling: A Practical Guide for Operations Teams
Jean-Thomas Rouzin - Reading time : 9 min
Table of contents
Geocoding errors do not just break maps. They drop conversion at checkout, distort delivery routing, and inflate cloud bills with silent retry storms. This guide explains how the Woosmap Geocoding API behaves when things go wrong, what your retry policy should look like in real-time and batch contexts, and how to size the operational budget that turns reliability into a board-level metric rather than a 3 AM page.
What "Geocoding API error handling" actually means
A geocoding API turns an address into coordinates, or coordinates into an address. Error handling is the set of decisions the calling code makes when the API does not return the answer the user is waiting for: client errors (bad input), server errors (the service is degraded), rate-limit responses (you are sending too many requests too fast), and transport errors (the network dropped the connection).
For most production teams using the Woosmap Localities Geocode API, error handling sits between two unrelated risks. One is user-facing: a failed geocode at the address-entry step is felt as cart abandonment, not as an exception in a log. The other is back-office: a batch geocoding job that retries blindly on a 429 can multiply spend without adding value. The right policy looks different for each.
Why error handling matters more for conversion than for uptime
Most "API error handling" articles frame the problem as a reliability question. The honest framing for a decision-maker is that the costliest errors are the ones the user does not understand.
A checkout form that fails an address lookup once, with no fallback, will lose the visitor. Industry-standard A/B tests on checkout friction consistently show that any friction added to address entry erodes conversion. The exact magnitude depends on the merchant, but the direction is unambiguous: errors at the autocomplete or geocode step at the moment of intent are the most expensive errors in the funnel.
The same 429 in a nightly batch job is cheap. It will be retried tomorrow, or in the next scheduled run, with no business impact. Treating both errors with the same retry policy is the mistake that keeps surfacing in incident reviews.
How to handle the four error classes
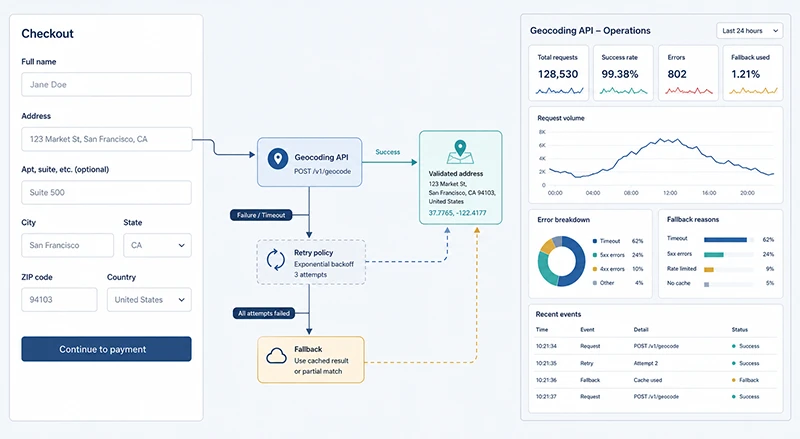
The Woosmap Geocoding API uses standard HTTP semantics. The error classes that matter in production are 4xx, 429, 5xx, and transport-layer failures. Each one tells you something different about what to do next.
4xx client errors
A 4xx response means the request was rejected because of something in the request itself. The most common ones are 400 (the input was malformed: missing parameters, invalid coordinates, unsupported country code) and 401 / 403 (the API key is missing, revoked, or restricted to a domain that does not match the caller).
Do not retry 4xx errors. They are deterministic: the same request will fail the same way. Log the request payload (minus any personal data), surface a clean message to the user when the request is user-facing, and route the alert to the on-call channel for any 401 or 403 - those are configuration bugs that block every downstream user, not transient incidents.
A 404 from a geocoder is interesting and worth handling distinctly. It does not always mean the address does not exist. It often means the address is not yet ingested for the country, the input contains a typo the parser cannot recover, or the request hit a coverage gap. The Woosmap Localities Geocode API publishes ROOFTOP-accurate worldwide coverage with documented exceptions (China mainland, North Korea, South Korea, and Japan). If your traffic includes those markets, plan a non-Woosmap fallback or a graceful degradation, not a retry.
429 rate-limiting
A 429 response means you have exceeded the request rate the platform allows for your plan tier. This is the error class that most teams handle wrong. The instinct is to retry immediately, or to retry with a fixed delay. Both make the problem worse: the second request meets the same throttle, the server spends cycles on rejected requests, and you spend the same budget twice.
The correct response is to throttle on the client side before you hit the 429, using a token bucket or a leaky bucket. Use the 429 as a signal to widen the interval until the bucket refills, with a small amount of jitter so that all your application servers do not retry in the same second. The official Woosmap pricing page describes the volume tiers and free monthly quotas; production teams should treat those numbers as a contract with their own throttling code, not as something to discover at 11 AM on Black Friday.
Two specifics matter for the Woosmap Geocoding API. Localities Autocomplete is free at all volumes; you cannot exhaust quota on autocomplete by definition, so a 429 on autocomplete is rare and almost always a sign of upstream burst protection rather than plan limits. Localities Geocode (the address-to-coordinates endpoint) does have plan-based volume tiers, and free tiers start at 10,000 requests per month before paid tiers apply. Build the throttle once, against your contracted volume, and update it when your plan changes.
5xx server errors
A 5xx means the service itself returned an error. Common cases are 500 (unhandled server-side exception), 502 / 503 (upstream component temporarily unavailable), and 504 (timeout at an intermediary). These are the only error class where retry-with-exponential-backoff is the canonical answer.
A reasonable starting policy is three retries with exponential backoff (one second, two seconds, four seconds) plus jitter of plus or minus a quarter of that interval. Hard-cap the total budget the retry loop is allowed to consume: if the request is user-facing, the cap is usually less than two seconds total, because past that point you have already lost the interaction. If the request is in a batch worker, the cap can be longer because no human is waiting.
The Woosmap Enterprise plan publishes a 99.9% SLA on the public pricing page. That works out to a budget of roughly forty-three minutes of unavailability per month before the SLA is breached. For most retailers, that budget will be consumed not in a single incident but distributed across small, transient 5xx clusters that the retry loop catches without anyone noticing. The 5xx budget you should reason about in capacity planning is the retry attempts you expect to see in steady state, not the worst case.
Transport-layer failures
Connection resets, DNS failures, TLS handshake failures, and request timeouts never reach an HTTP status code. They look like a thrown exception in the client SDK, and they can have causes that are entirely outside the API provider: a flaky egress link, a misconfigured firewall, a CDN node failing over.
Handle these the same way you handle 5xx (retry with backoff), but cap the per-request timeout aggressively. A user-facing geocode request should give up at 1.5 to 2 seconds total wall time. A batch worker can wait longer, but it should still bound the call: an unbounded request multiplied by a million rows in a batch is how you discover that your worker pool is exhausted at midnight.
Implementation patterns
The retry policy that works for your checkout is not the policy that works for your data warehouse. Pick one of the two patterns below; do not try to make a single library handle both.
Pattern A: Real-time, user-facing
Used at checkout, in store-locator search bars, and in any place where a human is waiting.
Per-request timeout: 1.5 to 2 seconds wall time, including TLS handshake.
Retry only on 5xx and transport errors. Never on 4xx, never on 429.
Maximum one retry. Past that, fail open: show the user a fallback flow (free-text address entry, manual city / postal code field) instead of an error screen.
Token bucket client-side throttle sized to 80% of your plan rate, so that 429s are exceptional and visible.
Surface 5xx and 429 rates on your conversion dashboard, not just on the infrastructure dashboard. They will correlate with cart abandonment when they spike.
The reason the retry budget is so tight is that the cost of waiting more than two seconds for an autocomplete suggestion is, almost always, that the user gives up and types the address by hand. The error-handling design has already failed at that point.
Pattern B: Batch, server-side
Used at nightly enrichment runs, address-data cleanup, and offline analytics.
Per-request timeout: 5 to 10 seconds wall time.
Retry on 5xx, transport errors, and 429 - with very different policies. 5xx: three retries with exponential backoff. 429: pause the entire worker pool for the duration the API tells you to wait, or for a heuristic if the API does not return a Retry-After header.
Persist the batch progress to a queue or a checkpoint table. Restartability matters more than per-request retry counts: a worker that dies cleanly mid-batch and resumes is cheaper to operate than one that holds state in memory.
Cap concurrency to your plan rate. Most batch incidents in this class come from the team that launches "twenty workers in parallel because it is faster" without telling the API team.
The architecture decision in batch is not "how aggressive should the retry be". It is "how do I make this restartable so retries cost almost nothing".
Monitoring: what to put on the dashboard
Three signals are worth tracking specifically for geocoding error handling, and they are not the obvious ones.
The first is the rate of 4xx responses, broken down by status code. A rising 400 rate is usually a regression in how your front-end builds the request. A rising 401 / 403 rate is almost always a credential rotation that did not propagate. Treat these as configuration alerts, not as service alerts.
The second is the ratio of 429s to total requests, plotted alongside the burst rate your token bucket allows. If those lines drift apart, your throttle is misconfigured for your actual plan, and you are paying for retries that the bucket should have prevented.
The third is the conversion impact: tag every geocode request with the funnel step it is serving (autocomplete on the cart, geocode at order confirmation, batch enrichment), and aggregate failure rates by tag. A 1% failure rate on autocomplete is a conversion incident; the same 1% on batch enrichment is operational noise. The dashboard that does not separate them will not help you prioritize during an incident.
Tools and resources
For most teams running the Woosmap Geocoding API, three documents earn a place in the operational runbook.
The first is the Woosmap Localities Geocode reference, which lists the endpoint contract, accuracy levels (ROOFTOP being the most precise), and request parameters. Keep a copy of the country-coverage exception list (China mainland, North Korea, South Korea, Japan) close to your fallback decision tree.
The second is the Woosmap pricing page, which publishes the volume tiers and free-tier quotas your throttle code is supposed to enforce. Treat it as the source of truth for plan limits, not internal tribal knowledge.
The third is a short, written, team-owned playbook that codifies the retry policies above for your specific stack. The single most predictive variable for a clean incident review is whether such a document existed before the incident.
For broader context on how location APIs fit into the larger maps-platform decision, see our Google Maps API alternatives guide which walks through the comparison landscape.
Where to go next
If you are sizing the operational budget for a geocoding implementation, the natural next step is to look at the Woosmap pricing page to map your forecasted volume against the contracted quotas your retry policy should enforce.
If you are evaluating Woosmap against other providers from an operational-reliability angle, see Woosmap for an overview of the platform and how the Localities family fits into a wider location stack.
Frequently Asked Questions
What is the most common Woosmap Geocoding API error in production?
In our experience with B2B implementations, the most common production errors are 429 rate-limit responses caused by client-side throttle misconfiguration, not 5xx errors. The fix is almost always to add a token-bucket throttle sized to the contracted plan rate, with jitter on retry, before adjusting plan tier. A 5xx cluster, when it appears, is more visible but rarer.
Should I retry on 429?
Not the way most teams retry. Do not retry the exact failed request immediately. Use the 429 as a signal that your client-side rate is too high, slow the entire caller down for a brief interval, and resume below the threshold. Honor the Retry-After header if the API provides one. A blind retry on 429 will simply trigger another 429.
What timeout should I set for a geocoding call at checkout?
A wall-clock timeout of 1.5 to 2 seconds, including TLS handshake, is a reasonable starting point for user-facing requests. Past that point, the average user has already shifted attention, and the conversion has been damaged whether the API recovers or not. Batch workers can run longer per-request timeouts, but the work should be restartable.
Does the Woosmap free tier include the Geocoding API?
The Woosmap pricing page documents a 10,000 free request per month tier on most APIs, including Localities Geocode. Localities Autocomplete is free at all volumes. Premium UK and Ireland address tiers require a Pro or Enterprise plan. Verify the current quotas directly on the pricing page before sizing your throttle, because the published numbers are the contract your code should be enforcing.
How is geocoding error handling different from autocomplete error handling?
Autocomplete runs in the typing loop, so the budget for a single failure is roughly one keystroke - usually under 300 ms. Geocode runs at form submission, where the budget is closer to two seconds. The retry policy for autocomplete is essentially "do not retry, suggest the previous result"; the retry policy for geocode is one retry on 5xx, then fall back to manual address entry. Same API family, different policies.
What does the Woosmap SLA cover, and what does it not cover?
The Enterprise plan publishes a 99.9% SLA, which is the service-availability contract. It does not contractually guarantee that every address worldwide resolves with ROOFTOP precision; coverage and accuracy are described separately in the product documentation. Your error-handling design should treat coverage gaps (typically surfaced as 404 or low-accuracy results) as a separate concern from availability.
Should we monitor geocoding errors with our infrastructure tools or our conversion tools?
Both, but tagged. Infrastructure monitoring catches the cluster early; conversion monitoring sizes the impact. The two views answer different questions - "is the platform healthy" vs. "are we losing revenue right now" - and an operations team that only watches one will misread incidents.
This guide was written byJean-Thomas Rouzin, CEO of Woosmap. Jean-Thomas leads a European location intelligence platform serving 220+ enterprise clients across retail, logistics, and travel, processing 28B+ location context calls per year with a 99.9% SLA on the Enterprise plan.